2025
Modality-Dependent Memory Mechanisms in Cross-Modal Neuromorphic ComputingArxiv Under Review
Effiong Blessing, Chiung-Yi Tseng, Somshubhra Roy, Isaac Nkrumah, Junaid Rehman
Spiking Memory-augmented spiking neural networks (SNNs) promise energy-efficient neuromorphic computing, yet their generalization across sensory modalities remains unexplored. We present the first comprehensive cross-modal ablation study of memory mechanisms in SNNs, evaluating Hopfield networks, Hierarchical Gated Recurrent Networks (HGRNs), and supervised contrastive learning (SCL) across visual (N-MNIST) and auditory (SHD) neuromorphic datasets. Our systematic evaluation of five architectures reveals striking modality-dependent performance patterns: Hopfield networks achieve 97.68% accuracy on visual tasks but only 76.15% on auditory tasks (21.53 point gap), revealing severe modalityspecific specialization, while SCL demonstrates more balanced cross-modal performance (96.72% visual, 82.16% audio, 14.56 point gap). These findings establish that memory mechanisms exhibit task-specific benefits rather than universal applicability. Joint multi-modal training with HGRN achieves 94.41% visual and 79.37% audio accuracy (88.78% average), matching parallel HGRN performance through unified deployment. Quantitative engram analysis confirms weak cross-modal alignment (0.038 similarity), validating our parallel architecture design. Our work provides the first empirical evidence for modality-specific memory optimization in neuromorphic systems, achieving 603× energy efficiency over traditional neural networks.
Modality-Dependent Memory Mechanisms in Cross-Modal Neuromorphic ComputingArxiv Under Review
Effiong Blessing, Chiung-Yi Tseng, Somshubhra Roy, Isaac Nkrumah, Junaid Rehman
Spiking Memory-augmented spiking neural networks (SNNs) promise energy-efficient neuromorphic computing, yet their generalization across sensory modalities remains unexplored. We present the first comprehensive cross-modal ablation study of memory mechanisms in SNNs, evaluating Hopfield networks, Hierarchical Gated Recurrent Networks (HGRNs), and supervised contrastive learning (SCL) across visual (N-MNIST) and auditory (SHD) neuromorphic datasets. Our systematic evaluation of five architectures reveals striking modality-dependent performance patterns: Hopfield networks achieve 97.68% accuracy on visual tasks but only 76.15% on auditory tasks (21.53 point gap), revealing severe modalityspecific specialization, while SCL demonstrates more balanced cross-modal performance (96.72% visual, 82.16% audio, 14.56 point gap). These findings establish that memory mechanisms exhibit task-specific benefits rather than universal applicability. Joint multi-modal training with HGRN achieves 94.41% visual and 79.37% audio accuracy (88.78% average), matching parallel HGRN performance through unified deployment. Quantitative engram analysis confirms weak cross-modal alignment (0.038 similarity), validating our parallel architecture design. Our work provides the first empirical evidence for modality-specific memory optimization in neuromorphic systems, achieving 603× energy efficiency over traditional neural networks.
Memory-Augmented Spiking Networks: Synergisti Integration of Complementary Mechanisms for Neuromorphic VisionNICE 2026 Under Review
Effiong Blessing, Chiung-Yi Tseng, Isaac Nkrumah, Junaid Rehman
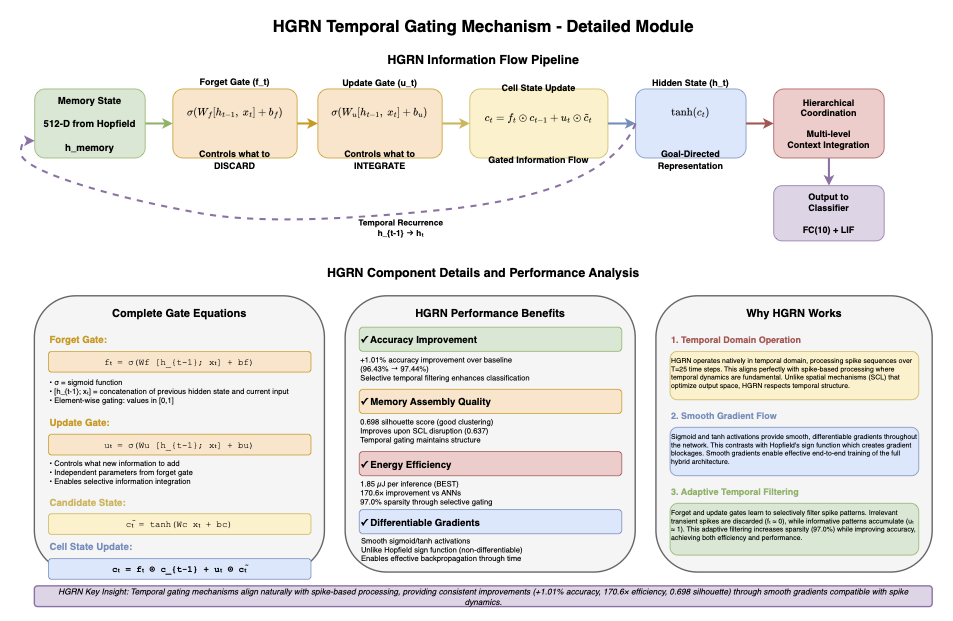
Spiking Neural Networks (SNNs) offer biological plausibility and energy efficiency, yet systematic investigation of memory augmentation strategies remains limited. We present five-model ablation studies, integrating Leaky Integrate-and-Fire neurons, Supervised Contrastive Learning (SCL), Hopfield networks, and Hierarchical Gated Recurrent Networks (HGRN) on N-MNIST. Our study shows: baseline SNNs naturally form organized group of neurons called structured assemblies (silhouette 0.687±0.012) that work together to process information in a neural network. Individual augmentations introduce trade-offs: SCL improves accuracy (+0.28%) but disrupts clustering (drop to silhouette 0.637±0.015); HGRN provides consistent gains (+1.01% accuracy, 170.6× efficiency); full integration achieves synergistic balance (silhouette 0.715±0.008, 97.49±0.10% accuracy, 1.85±0.06μJ, 97.0% sparsity). Optimal results emerge from architectural balance rather than individual optimization, establishing design principles for neuromorphic computing.
Memory-Augmented Spiking Networks: Synergisti Integration of Complementary Mechanisms for Neuromorphic VisionNICE 2026 Under Review
Effiong Blessing, Chiung-Yi Tseng, Isaac Nkrumah, Junaid Rehman
Spiking Neural Networks (SNNs) offer biological plausibility and energy efficiency, yet systematic investigation of memory augmentation strategies remains limited. We present five-model ablation studies, integrating Leaky Integrate-and-Fire neurons, Supervised Contrastive Learning (SCL), Hopfield networks, and Hierarchical Gated Recurrent Networks (HGRN) on N-MNIST. Our study shows: baseline SNNs naturally form organized group of neurons called structured assemblies (silhouette 0.687±0.012) that work together to process information in a neural network. Individual augmentations introduce trade-offs: SCL improves accuracy (+0.28%) but disrupts clustering (drop to silhouette 0.637±0.015); HGRN provides consistent gains (+1.01% accuracy, 170.6× efficiency); full integration achieves synergistic balance (silhouette 0.715±0.008, 97.49±0.10% accuracy, 1.85±0.06μJ, 97.0% sparsity). Optimal results emerge from architectural balance rather than individual optimization, establishing design principles for neuromorphic computing.
47B Mixture-of-Experts Beats 671B Dense Models on Chinese Medical ExaminationsarXiv preprint
Chiung-Yi Tseng, Danyang Zhang, Tianyang Wang, Hongying Luo, Lu Chen, Junming Huang, Jibin Guan, Junfeng Hao, Junhao Song, Ziqian Bi
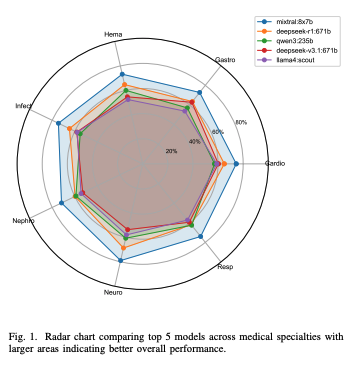
The rapid advancement of large language models (LLMs) has prompted significant interest in their potential applications in medical domains. This paper presents a comprehensive benchmark evaluation of 27 state-of-the-art LLMs on Chinese medical examination questions, encompassing seven medical specialties across two professional levels. We introduce a robust evaluation framework that assesses model performance on 2,800 carefully curated questions from cardiovascular, gastroenterology, hematology, infectious diseases, nephrology, neurology, and respiratory medicine domains. Our dataset distinguishes between attending physician and senior physician difficulty levels, providing nuanced insights into model capabilities across varying complexity. Our empirical analysis reveals substantial performance variations among models, with Mixtral-8x7B achieving the highest overall accuracy of 74.25%, followed by DeepSeekR1-671B at 64.07%. Notably, we observe no consistent correlation between model size and performance, as evidenced by the strong performance of smaller mixture-of-experts architectures. The evaluation demonstrates significant performance gaps between medical specialties, with models generally performing better on cardiovascular and neurology questions compared to gastroenterology and nephrology domains. Furthermore, our analysis indicates minimal performance degradation between attending and senior physician levels for top-performing models, suggesting robust generalization capabilities. This benchmark provides critical insights for the deployment of LLMs in medical education and clinical decision support systems, highlighting both the promise and current limitations of these technologies in specialized medical contexts.
47B Mixture-of-Experts Beats 671B Dense Models on Chinese Medical ExaminationsarXiv preprint
Chiung-Yi Tseng, Danyang Zhang, Tianyang Wang, Hongying Luo, Lu Chen, Junming Huang, Jibin Guan, Junfeng Hao, Junhao Song, Ziqian Bi
The rapid advancement of large language models (LLMs) has prompted significant interest in their potential applications in medical domains. This paper presents a comprehensive benchmark evaluation of 27 state-of-the-art LLMs on Chinese medical examination questions, encompassing seven medical specialties across two professional levels. We introduce a robust evaluation framework that assesses model performance on 2,800 carefully curated questions from cardiovascular, gastroenterology, hematology, infectious diseases, nephrology, neurology, and respiratory medicine domains. Our dataset distinguishes between attending physician and senior physician difficulty levels, providing nuanced insights into model capabilities across varying complexity. Our empirical analysis reveals substantial performance variations among models, with Mixtral-8x7B achieving the highest overall accuracy of 74.25%, followed by DeepSeekR1-671B at 64.07%. Notably, we observe no consistent correlation between model size and performance, as evidenced by the strong performance of smaller mixture-of-experts architectures. The evaluation demonstrates significant performance gaps between medical specialties, with models generally performing better on cardiovascular and neurology questions compared to gastroenterology and nephrology domains. Furthermore, our analysis indicates minimal performance degradation between attending and senior physician levels for top-performing models, suggesting robust generalization capabilities. This benchmark provides critical insights for the deployment of LLMs in medical education and clinical decision support systems, highlighting both the promise and current limitations of these technologies in specialized medical contexts.
StreetMath: Study of LLMs’ Approximation BehaviorsNeurips 2025 - MathAI WorkshopNeurips 2025 - WiML WorkshoparXiv preprint Poster
Chiung-Yi Tseng, Somshubhra Roy, Maisha Thasin, Blessing Effiong, Danyang Zhang
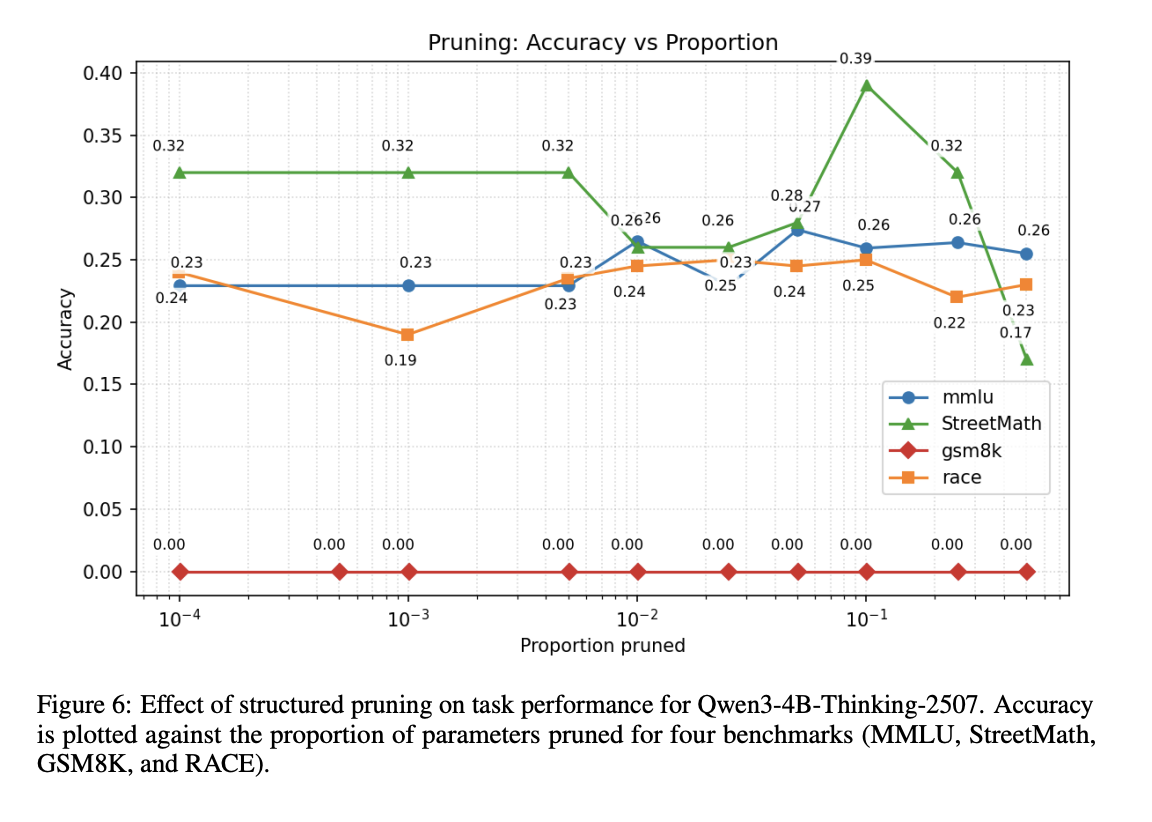
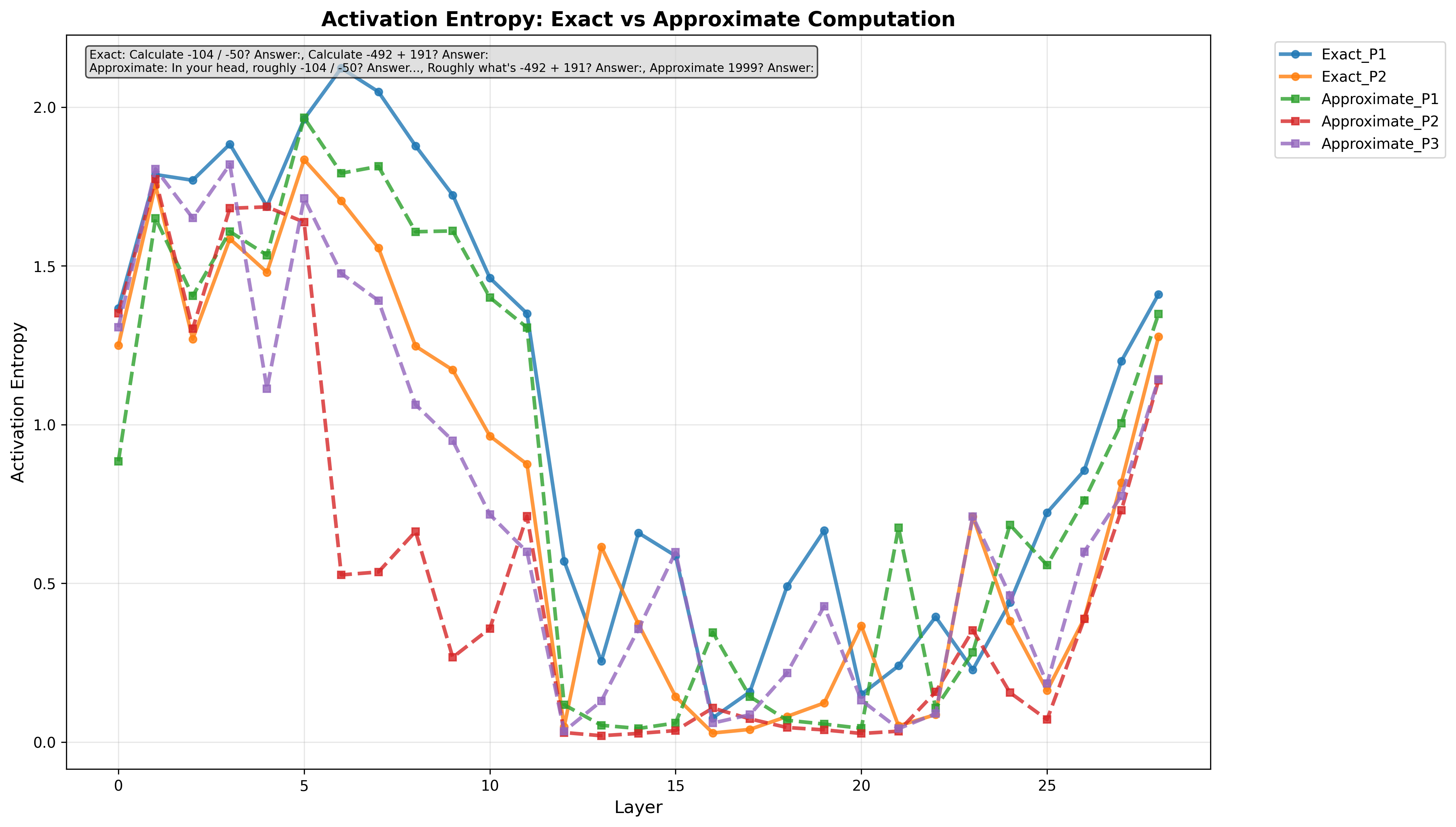
There is a substantial body of literature examining the mathematical reasoning capabilities of large language models (LLMs); particularly their performance on precise arithmetic operations in autoregressive architectures. However, their ability to perform approximate reasoning in informal fast-paced mathematical operations has received far less attention, especially among non-transformer models. Our work addresses this gap by introducing StreetMath, a benchmark designed to evaluate models’ approximation abilities under real-world approximation scenarios. We conduct extensive evaluations across different LLM architectures: Qwen3-4B-Instruct-2507, Qwen3-4B-Thinking-2507, Dream-v0-Instruct-7B, Falcon-Mamba-7B-Instruct and mamba-GPT-3B. Furthermore, we apply mechanistic interpretability techniques to probe their internal computational states. Our analysis reveals that LLMs generally attempt to compute exact values or invoke external tools even in tasks that call for approximation. Moreover, while models sometimes reach the correct answer in early layers or steps, they still consume more tokens when solving approximation tasks. Additional experiments indicate that exact and approximate arithmetic operations rely on largely separate neural components. These findings suggest that LLMs’ limited performance in approximation scenarios may stem from training corpora that predominantly emphasize exact arithmetic. Drawing upon research on cognitive psychology, we argue that LLMs do not exhibit cognitive miserliness in the same way humans do in street math settings. We open source our work https://github.com/ctseng777/StreetMath
StreetMath: Study of LLMs’ Approximation BehaviorsNeurips 2025 - MathAI WorkshopNeurips 2025 - WiML WorkshoparXiv preprint Poster
Chiung-Yi Tseng, Somshubhra Roy, Maisha Thasin, Blessing Effiong, Danyang Zhang
There is a substantial body of literature examining the mathematical reasoning capabilities of large language models (LLMs); particularly their performance on precise arithmetic operations in autoregressive architectures. However, their ability to perform approximate reasoning in informal fast-paced mathematical operations has received far less attention, especially among non-transformer models. Our work addresses this gap by introducing StreetMath, a benchmark designed to evaluate models’ approximation abilities under real-world approximation scenarios. We conduct extensive evaluations across different LLM architectures: Qwen3-4B-Instruct-2507, Qwen3-4B-Thinking-2507, Dream-v0-Instruct-7B, Falcon-Mamba-7B-Instruct and mamba-GPT-3B. Furthermore, we apply mechanistic interpretability techniques to probe their internal computational states. Our analysis reveals that LLMs generally attempt to compute exact values or invoke external tools even in tasks that call for approximation. Moreover, while models sometimes reach the correct answer in early layers or steps, they still consume more tokens when solving approximation tasks. Additional experiments indicate that exact and approximate arithmetic operations rely on largely separate neural components. These findings suggest that LLMs’ limited performance in approximation scenarios may stem from training corpora that predominantly emphasize exact arithmetic. Drawing upon research on cognitive psychology, we argue that LLMs do not exhibit cognitive miserliness in the same way humans do in street math settings. We open source our work https://github.com/ctseng777/StreetMath
Dream Diary: Case Study on Diffusion LLM’s Arithmetic BehaviorNeurips 2025 - WiML Workshop Poster
Chiung-Yi Tseng, Maisha Thasin, Blessing Effiong, Somshubhra Roy, Danyang Zhang
Mechanistic interpretability studies of autoregressive (AR) models are abundant, while studies on diffusion models (DLLM) remain less explored. In this study, we investigate the arithmetic behaviors of Dream-v0-Instruct-7B (Dream). Future work includes causal study of DLLM to isolate the arithmetic neurons [1], particularly approximation operations, extending the evaluation to larger benchmarks to gain statistical significance and providing mechanistic interpretability study tools to the community.
Dream Diary: Case Study on Diffusion LLM’s Arithmetic BehaviorNeurips 2025 - WiML Workshop Poster
Chiung-Yi Tseng, Maisha Thasin, Blessing Effiong, Somshubhra Roy, Danyang Zhang
Mechanistic interpretability studies of autoregressive (AR) models are abundant, while studies on diffusion models (DLLM) remain less explored. In this study, we investigate the arithmetic behaviors of Dream-v0-Instruct-7B (Dream). Future work includes causal study of DLLM to isolate the arithmetic neurons [1], particularly approximation operations, extending the evaluation to larger benchmarks to gain statistical significance and providing mechanistic interpretability study tools to the community.
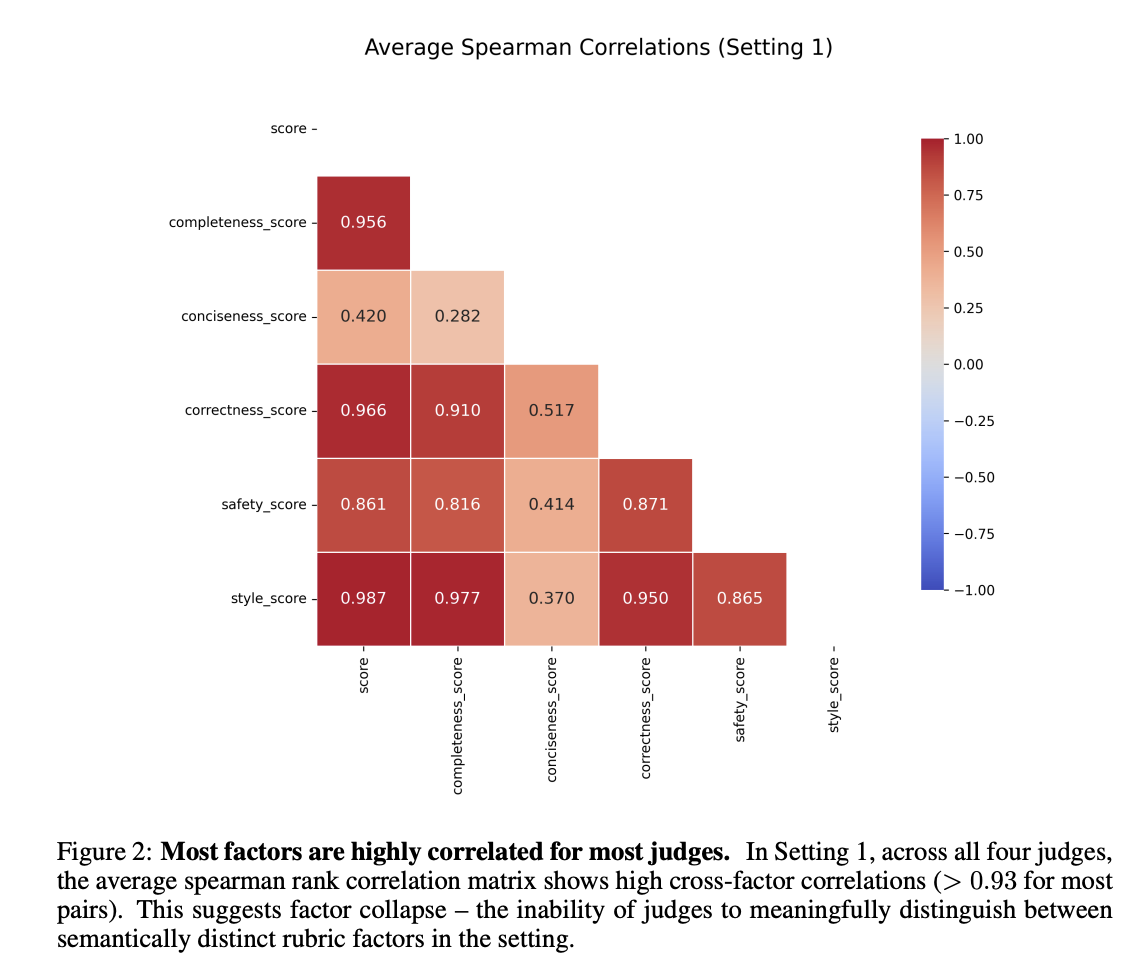
When Judgment Becomes Noise: How Design Failures in LLM Judge Benchmarks Silently Undermine Validity (Under Review)arXiv preprint Under Review
Benjamin Feuer, Chiung-Yi Tseng, Astitwa Sarthak Lathe, Oussama Elachqar, John P Dickerson
LLM-judged benchmarks are increasingly used to evaluate complex model behaviors, yet their design introduces failure modes absent in conventional, groundtruth–based benchmarks. We argue that, without tight objectives and verifiable constructions, benchmark rankings can produce high-confidence rankings that are in fact largely noise. We introduce two mechanisms to diagnose these issues. Schematic adherence quantifies how much of a judge’s overall verdict is explained by the explicit evaluation schema, revealing unexplained variance when judges deviate from their own rubric. Psychometric validity aggregates internal consistency and discriminant validity signals to quantify irreducible uncertainty in any benchmarking run. Applying these tools to Arena-Hard Auto, we find severe schema incoherence and factor collapse across popular judges: e.g., unexplained variance exceeding 90% for DeepSeek-R1-32B and factor correlations above 0.93 for most criteria. We also show that the ELO-style aggregation used by Arena-Hard Auto collapses and masks genuine ranking uncertainty. Our results highlight design failures that undermine validity and offer actionable principles for building better-scoped, reliability-aware LLM-judged benchmarks. We release our code at https://anonymous.4open.science/r/judgment-to-noise-947D/README.md
When Judgment Becomes Noise: How Design Failures in LLM Judge Benchmarks Silently Undermine Validity (Under Review)arXiv preprint Under Review
Benjamin Feuer, Chiung-Yi Tseng, Astitwa Sarthak Lathe, Oussama Elachqar, John P Dickerson
LLM-judged benchmarks are increasingly used to evaluate complex model behaviors, yet their design introduces failure modes absent in conventional, groundtruth–based benchmarks. We argue that, without tight objectives and verifiable constructions, benchmark rankings can produce high-confidence rankings that are in fact largely noise. We introduce two mechanisms to diagnose these issues. Schematic adherence quantifies how much of a judge’s overall verdict is explained by the explicit evaluation schema, revealing unexplained variance when judges deviate from their own rubric. Psychometric validity aggregates internal consistency and discriminant validity signals to quantify irreducible uncertainty in any benchmarking run. Applying these tools to Arena-Hard Auto, we find severe schema incoherence and factor collapse across popular judges: e.g., unexplained variance exceeding 90% for DeepSeek-R1-32B and factor correlations above 0.93 for most criteria. We also show that the ELO-style aggregation used by Arena-Hard Auto collapses and masks genuine ranking uncertainty. Our results highlight design failures that undermine validity and offer actionable principles for building better-scoped, reliability-aware LLM-judged benchmarks. We release our code at https://anonymous.4open.science/r/judgment-to-noise-947D/README.md
Diffusion-based Large Language Models SurveyTechRxiv Preprint Preprint
Chiung-Yi Tseng, Danyang Zhang, Ziqian Bi, Junhao Song
Diffusion-based large language models (DLLMs) have emerged as a promising alternative to traditional autoregressive architectures, notably enhancing parallel generation, controllability, and robustness across multiple modalities. Originally developed from continuous diffusion methods in computer vision, recent adaptations of DLLMs have tailored discrete diffusion processes through absorbing-state kernels, latent projections, and hybrid architectures. This survey reviews recent developments in DLLMs, beginning with their foundational concepts, including DDPM, DDIM, and their early discrete adaptations, such as mask-based, continuous-embedding, and hybrid models. We organize current methods by sampling strategy, guidance type, noise schedule, and temporal conditioning, and analyzes their efficiency, output quality, and fine-tuning. The paper also highlights key advancements: autoregressive-diffusion unification through hyperschedules, adaptive correction sampling, and efficient caching mechanisms to enhance computational performance. Besides, it explores emerging applications, such as natural language tasks, multimodal generation, and reasoning-intensive domains... These demonstrate the versatility of DLLMs. Furthermore, the paper identifies critical challenges, including adaptive sampling, scalable alignment strategies, deeper integration with pretrained language models, graph-based diffusion frameworks, and robust evaluation protocols. Finally, the paper proposes directions that could define future research in diffusion-based sequence generation.
Diffusion-based Large Language Models SurveyTechRxiv Preprint Preprint
Chiung-Yi Tseng, Danyang Zhang, Ziqian Bi, Junhao Song
Diffusion-based large language models (DLLMs) have emerged as a promising alternative to traditional autoregressive architectures, notably enhancing parallel generation, controllability, and robustness across multiple modalities. Originally developed from continuous diffusion methods in computer vision, recent adaptations of DLLMs have tailored discrete diffusion processes through absorbing-state kernels, latent projections, and hybrid architectures. This survey reviews recent developments in DLLMs, beginning with their foundational concepts, including DDPM, DDIM, and their early discrete adaptations, such as mask-based, continuous-embedding, and hybrid models. We organize current methods by sampling strategy, guidance type, noise schedule, and temporal conditioning, and analyzes their efficiency, output quality, and fine-tuning. The paper also highlights key advancements: autoregressive-diffusion unification through hyperschedules, adaptive correction sampling, and efficient caching mechanisms to enhance computational performance. Besides, it explores emerging applications, such as natural language tasks, multimodal generation, and reasoning-intensive domains... These demonstrate the versatility of DLLMs. Furthermore, the paper identifies critical challenges, including adaptive sampling, scalable alignment strategies, deeper integration with pretrained language models, graph-based diffusion frameworks, and robust evaluation protocols. Finally, the paper proposes directions that could define future research in diffusion-based sequence generation.
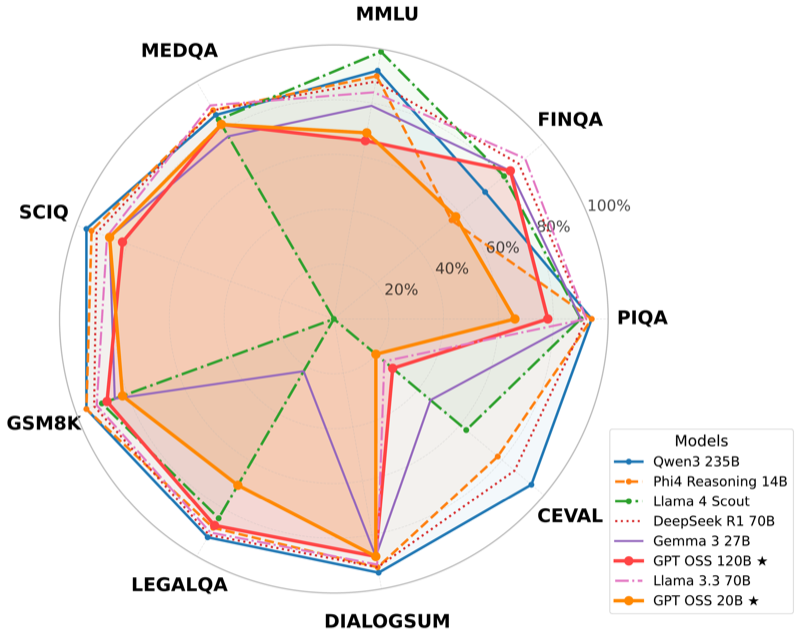
Is GPT-OSS Good? A Comprehensive Evaluation of OpenAI's Latest Open Source ModelsarXiv preprint
Ziqian Bi*, Keyu Chen*, Chiung-Yi Tseng*, Danyang Zhang*, Tianyang Wang, Hongying Luo, Lu Chen, Junming Huang, Jibin Guan, Junfeng Hao, Junhao Song (* equal contribution)
This paper evaluates OpenAI's first open weight large language models since GPT-2, comparing two mixture of experts models (120B and 20B parameters) against six contemporary open source models. Our comprehensive evaluation reveals that gpt-oss-20B consistently outperforms gpt-oss-120B on several benchmarks, providing important insights into the performance characteristics of these newly released models.
Is GPT-OSS Good? A Comprehensive Evaluation of OpenAI's Latest Open Source ModelsarXiv preprint
Ziqian Bi*, Keyu Chen*, Chiung-Yi Tseng*, Danyang Zhang*, Tianyang Wang, Hongying Luo, Lu Chen, Junming Huang, Jibin Guan, Junfeng Hao, Junhao Song (* equal contribution)
This paper evaluates OpenAI's first open weight large language models since GPT-2, comparing two mixture of experts models (120B and 20B parameters) against six contemporary open source models. Our comprehensive evaluation reveals that gpt-oss-20B consistently outperforms gpt-oss-120B on several benchmarks, providing important insights into the performance characteristics of these newly released models.
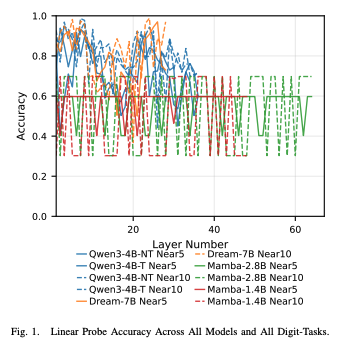
Decipher Deep Math: Numeric Rounding Behaviors in LLMsDeepMath-2025 Accepted
Chiung-Yi Tseng, Maisha Thasin, Danyang Zhang, Blessing Effiong, Somshubhra Roy
This research investigates how language models understand and process numerical rounding tasks through linear probing techniques. We analyze the internal representations of various model architectures to understand how they encode proximity to multiples of 5 and 10. Our study implements streaming linear probes that process activations in batches rather than storing entire activation matrices, enabling memory-efficient analysis across multiple architectures including Transformer-based models (Qwen, Dream) and State Space Models (Mamba). Through layer-wise analysis, we identify which layers in different architectures best encode numerical proximity information and reveal significant differences between "thinking" and "non-thinking" model variants.
Decipher Deep Math: Numeric Rounding Behaviors in LLMsDeepMath-2025 Accepted
Chiung-Yi Tseng, Maisha Thasin, Danyang Zhang, Blessing Effiong, Somshubhra Roy
This research investigates how language models understand and process numerical rounding tasks through linear probing techniques. We analyze the internal representations of various model architectures to understand how they encode proximity to multiples of 5 and 10. Our study implements streaming linear probes that process activations in batches rather than storing entire activation matrices, enabling memory-efficient analysis across multiple architectures including Transformer-based models (Qwen, Dream) and State Space Models (Mamba). Through layer-wise analysis, we identify which layers in different architectures best encode numerical proximity information and reveal significant differences between "thinking" and "non-thinking" model variants.
Active Learning Methods for Efficient Data Utilization and Model Performance EnhancementarXiv preprint Preprint
Junhao Song, Ziqian Bi, Tianyang Wang, Chia Xin Liang, Chiung-Yi Tseng, Ming Liu
In the era of data-driven intelligence, the paradox of data abundance and annotation scarcity has emerged as a critical bottleneck in the advancement of machine learning. This paper gives a detailed overview of Active Learning (AL), which is a strategy in machine learning that helps models achieve better performance using fewer labeled examples. It introduces the basic concepts of AL and discusses how it is used in various fields such as computer vision, natural language processing, transfer learning, and real-world applications. The paper focuses on important research topics such as uncertainty estimation, handling of class imbalance, domain adaptation, fairness, and the creation of strong evaluation metrics and benchmarks. It also shows that learning methods inspired by humans and guided by questions can improve data efficiency and help models learn more effectively. In addition, this paper talks about current challenges in the field, including the need to rebuild trust, ensure reproducibility, and deal with inconsistent methodologies. It points out that AL often gives better results than passive learning, especially when good evaluation measures are used. This work aims to be useful for both researchers and practitioners by providing key insights and proposing directions for future progress in active learning.
Active Learning Methods for Efficient Data Utilization and Model Performance EnhancementarXiv preprint Preprint
Junhao Song, Ziqian Bi, Tianyang Wang, Chia Xin Liang, Chiung-Yi Tseng, Ming Liu
In the era of data-driven intelligence, the paradox of data abundance and annotation scarcity has emerged as a critical bottleneck in the advancement of machine learning. This paper gives a detailed overview of Active Learning (AL), which is a strategy in machine learning that helps models achieve better performance using fewer labeled examples. It introduces the basic concepts of AL and discusses how it is used in various fields such as computer vision, natural language processing, transfer learning, and real-world applications. The paper focuses on important research topics such as uncertainty estimation, handling of class imbalance, domain adaptation, fairness, and the creation of strong evaluation metrics and benchmarks. It also shows that learning methods inspired by humans and guided by questions can improve data efficiency and help models learn more effectively. In addition, this paper talks about current challenges in the field, including the need to rebuild trust, ensure reproducibility, and deal with inconsistent methodologies. It points out that AL often gives better results than passive learning, especially when good evaluation measures are used. This work aims to be useful for both researchers and practitioners by providing key insights and proposing directions for future progress in active learning.